为什么聪明的AI也会「犯迷糊」?一个科研团队用ReCALL治愈了多模态大模型的检索「失忆症」
想象一下,你有一个聪明的朋友,他能轻松回答「这张图里有几只猫」「那只狗是什么颜色」这样的问题。但突然有一天,你让他帮你找一张特定的图片时,他却完全懵了——明明是很简单的描述,他却总是找错。
这听起来是不是很荒谬?但这恰恰是过去一年多里,整个AI学术界都在面对的真实困境。
聪明的AI为何在找图时变得「迟钝」
多模态大模型(MLLM)有多强大?它们能看图说话、能推理逻辑、在各种视觉问答任务上表现惊艳。正因如此,当研究者们想把它们应用到图像检索领域时,理所当然地认为这是降维打击。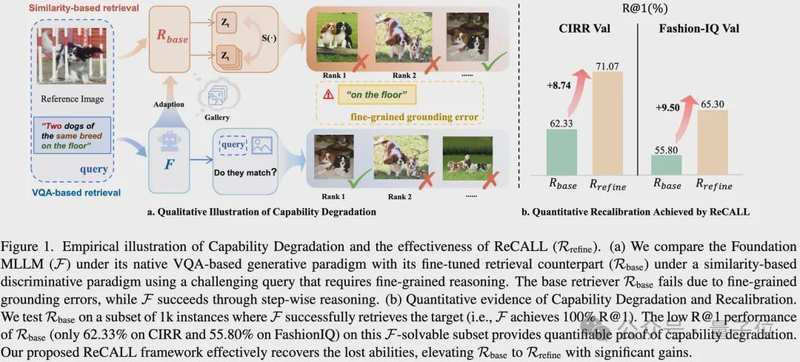
然而现实给了所有人一记重锤。当研究人员把生成式的大模型强行改造成判别式检索器后,模型出现了严重的能力退化——原本100%能解决的问题,开始频繁出错。定量数据显示,在原本模型能完全答对的测试集上,传统微调后的检索器准确率直接腰斩。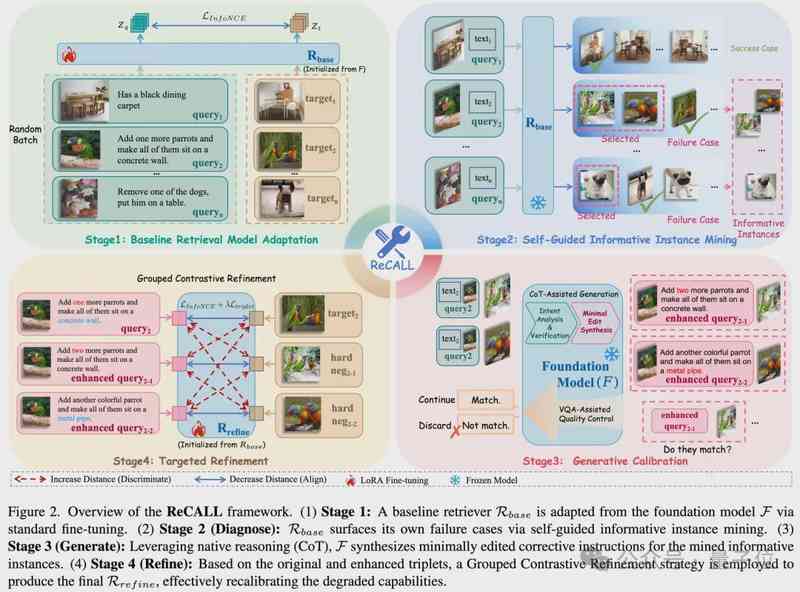
这让很多人百思不得其解:明明是同一个模型,为什么做检索就变笨了?
一场关于「范式冲突」的深度追问
紫东太初团队和新加坡国立大学的研究者们没有止步于现象描述。他们深入挖掘后,找到了问题的本质:范式冲突。
通俗地讲,大模型天生习惯的是「生成式」思维——看到图片后,它会一步步推理、细细分析。但传统检索方法要求模型把所有的思考压缩成一个小小的向量,然后通过计算相似度来匹配。这就好比你让一个思维缜密的辩手,必须用一句话回答所有复杂问题——信息的大量丢失在所难免。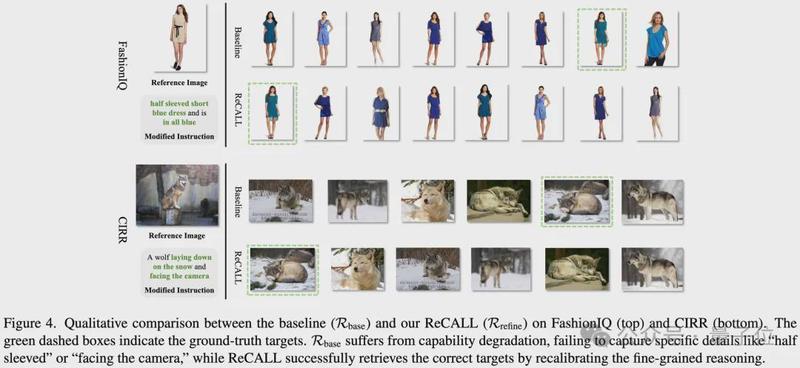
这种「暴力压缩」直接导致了能力的退化。模型原有的细粒度推理天赋,在单一的向量空间中荡然无存。
ReCALL的破局之道:「错题本」式的自我修正
面对这个问题,研究团队没有选择继续修修补补,而是从教育学中找到了灵感——错题本。
ReCALL框架的核心逻辑是:让大模型自己当自己的老师。整个过程分为四步走。首先,用标准方法微调出一个基础检索器,让它暴露问题;其次,让这个基础检索器在训练集上「自检」,专门找出那些它自信满满但实际找错了的样本——这些就是模型的认知盲区;然后,把这些错题交给原生的大模型,让它用链式思考(CoT)详细分析到底哪里出了问题,并生成精准的纠错指令;最后,用这些精心设计的纠错数据,对检索器进行针对性的「补习」。
第三步是整个方案最精妙的地方。研究团队设计了一套名为「最小编辑合成」的机制:大模型不会被要求凭空创作,而是只在错误答案和正确答案之间,找到那一点点微小的差异,用最小幅度的文字编辑来描述这种差异。这种方式既保证了生成的准确性,又维护了与原始数据分布的一致性。
配合VQA级别的语义过滤,所有可能出现的幻觉和噪音都被严格剔除。最终送入模型的「纠错信号」,堪称精准且高保真。
从「盲目对齐」到「诊断-生成-内化」
ReCALL的效果在CIRR、FashionIQ等主流基准测试中得到了充分验证。55.52%的R@1刷新了CIRR的SOTA记录,细粒度子集上的81.49%更是令人惊艳。
比数字更有意义的是它揭示的深层规律:大模型做检索,不应该是粗暴的降维压缩。当我们换一种思路——不再用海量外部数据「喂养」检索器,而是教会模型用自己的思维链去剖析错题、缝合认知盲区——它不仅找回了丢失的细粒度感知,更展示了生成与判别两大范式走向和解的可能。
这或许预示着多模态大模型在垂直领域真正实现「能力无损适配」的重要一步。而这一切的开始,仅仅是研究者们愿意多问一句:「为什么聪明的AI也会犯迷糊?」